
Programming
| No. | 506 |
| Name. | swindler |
| Subject. | The Boyer-Moore Algorithm |
| Main Cate. | 개발일반 |
| Sub Cate. | |
| Date. | 2008-12-04 10:17 |
| Hit. | 4149 (210.182.190.136) |
| File. |
bm.gif 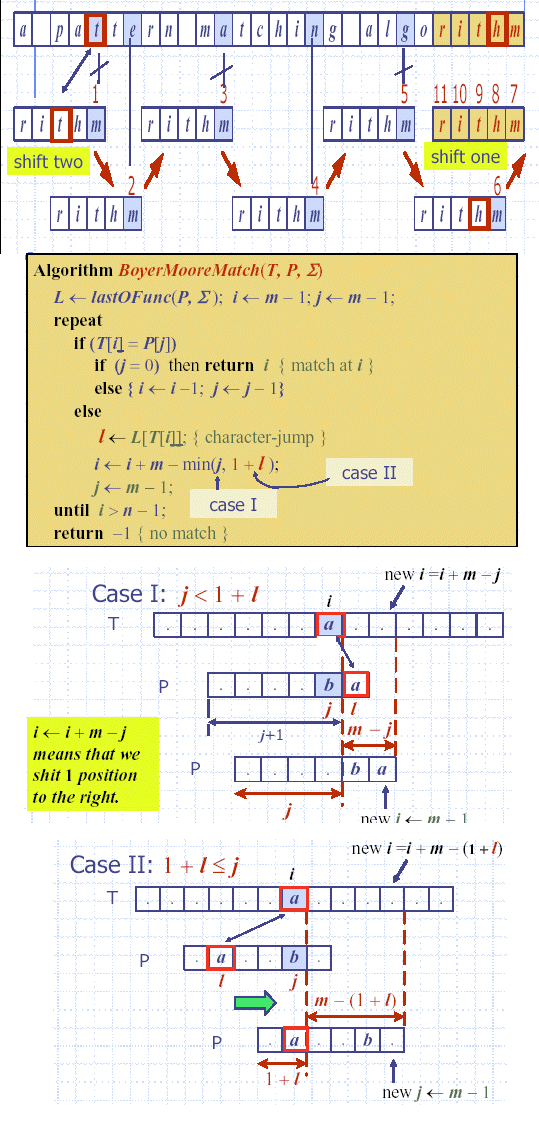
|
| : P와 sizable fraction of T의 비교를 줄여준다. Brute-Force 알고리즘은 unbounded alphabet에서도 사용 가능하지만, BM 알고리즘은 finite size에서만 가능하다. => alphabet이 moderately sized하고 pattern이 상대적으로 길 때 가장 빠르다. (*) Two heuristics 1. Looking-Glass Heuristic : P의 제일 뒤부터 compare한다. 2. Character-Jump Heuristic : mismatch 일어나면 (T[i] = c), pattern에서 'c' 포함하면 (역시 backward로 검사) 거기까지 pattern shifting, pattern에 'c'가 없으면 그 다음까지 pattern 모~두 shifting => last occurrence function 만들어 사용. (*) Last-Occurrence Function L(c) = P[i]의 가장 큰 인덱스 i (pattern에 포함 안되면 -1) Pattern을 뒤에서 앞으로 한 번 scan해야하고, alphabet 전체도 한 번 scan해야하므로 (-1인 것 찾기) last-Occurrence Function의 TC = O(m+s) // s는 alphabet size Boyer-Moore pattern matching (case1 은 last occurrence가 j를 pass 한 경우 그냥 한 칸만 shift 하는 것이다.) worst-case : T = aaaa.....a, P = baaa....a 일 때. O(nm + s) 가 된다. 거의, Brute-Force 알고리즘이랑 막상막하 그러나, English text와 같은 text에서는 skip이 많이 일어나서 효과적이다. experimental evidence로, 5 문자 pattern string에서는 비교가 0.24번 일어났다. 그리고, 이 것은 simplified된 BM 알고리즘이고, 실제는 다른 shift heuristic(KMP에서 아이디어)을 사용하여, running time은 O(n+m+s)이다.
[바로가기 링크] : http://coolx.net/cboard/develop/506 |
|
|
|
|
| [Modify] [Delete] | [Reply] [List] | |
 Copyright © 1999-2017, swindler. All rights reserved.
367,611 visitor ( 1999.1.8-2004.5.26 ), 2,405,771 ( -2017.01.31)
Copyright © 1999-2017, swindler. All rights reserved.
367,611 visitor ( 1999.1.8-2004.5.26 ), 2,405,771 ( -2017.01.31)